
La caracterización de la estructura de la comunidad de las redes complejas
Andrea Lancichinetti, Mikko Kivelä, Jari Saramäki, Santo Fortunato
Publicado: 12 de agosto de 2010 | http://dx.doi.org/10.1371/journal.pone.0011976
Resumen
Trasfondo
La estructura de la comunidad es una de las propiedades fundamentales de las redes complejas y desempeña un papel crucial en su topología y función. Mientras que una cantidad impresionante de trabajo se ha hecho sobre la cuestión de la detección de la comunidad, muy poca atención se ha dedicado hasta ahora a la investigación de las comunidades en las redes reales.Metodología / Principales conclusiones
Se presenta un análisis empírico sistemático de las propiedades estadísticas de las comunidades en la información general, la comunicación, tecnológicos, biológicos, y las redes sociales. Nos encontramos con que la organización mesoscópica de las redes de la misma categoría es notablemente similar. Esto se refleja en varias características de la estructura de la comunidad, que pueden ser utilizados como "huellas dactilares" de categorías específicas de la red. Mientras que las distribuciones de tamaño de la comunidad son siempre amplio, ciertas categorías de redes consisten principalmente en las comunidades en forma de árbol, mientras que otros tienen módulos más densos. ruta longitudes medias dentro de las comunidades inicialmente crecen logarítmicamente con el tamaño de la comunidad, pero se satura el crecimiento se ralentiza o para las comunidades más grandes que un tamaño característico. Este comportamiento está relacionado con la presencia de los centros dentro de las comunidades, cuyas funciones difieren entre categorías. También la inserción comunitaria de nodos, medido en términos de la fracción de enlaces dentro de sus comunidades, tiene una distribución característica para cada categoría.Conclusiones / Importancia
Nuestros resultados, verificados por el uso de dos métodos de detección comunidad fundamentalmente diferentes, permiten una clasificación de las redes reales y allanan el camino a un modelado realista de la evolución de redes '.
Introducción
La moderna ciencia de los sistemas complejos ha experimentado un avance significativo después del descubrimiento de que la representación gráfica de este tipo de sistemas, a pesar de su simplicidad, revela un conjunto de características cruciales que son suficientes para revelar sus propiedades, función y evolución mecanismos estructurales generales [1] - [ 8]. Que representa un sistema complejo como un grafo que significa convertir las unidades elementales del sistema en los nodos, mientras que los enlaces entre nodos indican sus interacciones o relaciones mutuas. Muchas redes complejas se caracterizan por una amplia distribución del número de vecinos de un nodo, es decir, su grado. Esto es responsable de las propiedades peculiares tales como alta robustez frente a fallos aleatorios [9] y la ausencia de un umbral para la propagación de epidemias [10].Otra característica importante de las redes complejas está representado por su estructura mesoscopic, caracterizado por la presencia de grupos de nodos, denominados comunidades o módulos, con una alta densidad de enlaces entre los nodos de un mismo grupo y una relativamente baja densidad de enlaces entre los nodos de diferentes grupos [11] - [14]. Esta organización compartimental de las redes es muy común en los sistemas de origen diverso. Ya se comentó en la década de 1960 que una estructura modular jerárquica es necesario para la robustez y estabilidad de los sistemas complejos, y les da una ventaja evolutiva [15].
La exploración de las comunidades de la red es importante por tres razones principales: 1) para revelar organización de la red a un nivel grueso, lo que puede ayudar a formular mecanismos realistas para su génesis y evolución; 2) para entender mejor los procesos dinámicos que tienen lugar en la red (por ejemplo, los procesos de innovación y epidemias), que pueden verse afectados considerablemente por la estructura modular del grafo de difusión; 3) para descubrir relaciones entre los nodos que no son aparentes mediante la inspección de la gráfica como un todo y que por lo general se pueden atribuir a la función del sistema.
Por lo tanto, no es sorprendente que los últimos años han sido testigos de una explosión de investigación sobre la estructura de la comunidad en los grafos. El problema principal, por supuesto, es la forma de detectar las comunidades, en primer lugar, y este es el punto esencial empujón por parte de la mayoría de los artículos sobre el tema que han aparecido en la literatura. Un gran número de métodos y técnicas se han diseñado, pero la comunidad científica todavía no ha acordado cuáles son los métodos más fiables y cuando un método deben o no deben ser adoptadas. Esto es debido al hecho de que está mal definida el concepto de comunidad. Dado que la atención se ha centrado en el desarrollo del método, muy poco se ha hecho hasta ahora para abordar una cuestión fundamental de este esfuerzo: ¿qué comunidades en redes reales parecen? Esto es lo que vamos a tratar de evaluar en este documento.
Investigaciones anteriores han demostrado que a través de una amplia gama de redes, la distribución de tamaños de la comunidad es amplio, con muchas pequeñas comunidades que coexisten con algunos otros mucho más grandes [12], [16] - [19]. La cola de la distribución puede ser a menudo bastante bien equipado por una ley de potencia. Leskovec et al. [20] han llevado a cabo una investigación exhaustiva de la calidad de las comunidades en las redes reales, medido por la puntuación de la conductancia [21]. Encontraron que la conductancia más bajo, lo que indica módulos bien definidos, se alcanza a las comunidades de un tamaño característico de los nodos, mientras que las comunidades mucho más grandes son más "mezclarse" con el resto de la red. Por esta razón se sugiere que la organización mesoscopic de redes puede tener una estructura de núcleo-periferia, donde la periferia se compone de pequeñas comunidades bien definidas y el núcleo comprende módulos más grandes, que están conectados más densamente entre sí y por lo tanto más difícil de detectar. Guimerá y Amaral han propuesto una clasificación de los nodos basados en sus roles dentro de las comunidades [22].
Sin embargo, las propiedades fundamentales de las comunidades en las redes reales siguen siendo en su mayoría desconocidos. El descubrimiento de estas propiedades es el objetivo principal de este trabajo. Con este fin, hemos realizado un extenso análisis estadístico de la estructura de la comunidad de muchas redes reales de la naturaleza, la sociedad y la tecnología. La principal conclusión es que las comunidades se caracterizan por rasgos distintivos, que son comunes para las redes de la misma clase, pero que difieren de una clase a otra. Cabe destacar que dicha caracterización es independiente del método específico adoptado para encontrar las comunidades.
Métodos
Como nuestro objetivo es estudiar las características estadísticas de las comunidades, es necesario emplear conjuntos de datos en las redes grandes que contienen un gran número de comunidades de tamaño variable. Nuestros conjuntos de datos contienen los nodos, con excepción de las redes de interacción de proteínas (PIN), donde los más grandes conjuntos de datos disponibles son del orden de los nodos.La Tabla 1 enumera los conjuntos de datos de red que hemos utilizado, junto con algunas estadísticas básicas. La mayoría de ellos han sido descargados de la red grande de conjunto de datos de la colección de Stanford (http://snap.stanford.edu/data/). Algunas redes están dirigidas originalmente (por ejemplo, el grafo de la web), pero los hemos tratado como no dirigida. Para más detalles sobre todas las redes se pueden encontrar en el Apéndice S1.
Table 1. Lista de datos de red usadas para el análisis

En general, hemos tenido en cuenta cinco categorías de redes:
- Redes de comunicación. Esta clase comprende la red de correo electrónico de una gran institución europea de investigación, y un conjunto de relaciones entre los usuarios de Wikipedia que se comunican a través de sus páginas de discusión. Tenga en cuenta que en los dos casos, la comunicación no es necesariamente personal, sino que implica, por ejemplo, correos electrónicos en masa, y por lo tanto estas redes no se puede considerar como redes sociales.
- Internet. Aquí tenemos dos mapas de Internet a nivel de sistemas autónomos (AS) (es decir, los nodos son grupos de enrutadores administrados por una sola entidad), producidas por los dos principales proyectos que exploran la topología de Internet: CAIDA (http: // www .caida.org /) y diez centavos (http://www.netdimes.org/).
- Redes de información. Esta clase incluye una red cita de pre-impresiones en línea en www.arxiv.org, una red de co-compra de los artículos vendidos por www.amazon.com y dos muestras de la gráfica Web, uno en representación de la berkeley.edu dominios y stanford.edu ( web-BS), y el otro fue lanzado por Google (web-G).
- Redes biológicas. Esta clase contiene los conjuntos de interacciones entre proteínas de tres organismos: mosca de la fruta (Drosophila melanogaster), levadura (Saccharomyces cerevisiae) y el hombre (Homo sapiens).
- Redes sociales. Aquí hemos considerado cuatro conjuntos de datos: una red de relaciones de amistad entre los usuarios de la comunidad en línea LiveJournal (www.livejournal.com); el conjunto de las relaciones de confianza entre los usuarios del sitio epinions.com opinión de los consumidores; la red de amistad de los usuarios del slashdot.org; la red de los usuarios de friedship www.last.fm.
El problema de la elección de un método para la detección de las comunidades es muy delicada. En primer lugar, se necesitan algoritmos muy eficiente, debido a que las redes que estudiamos son grandes. Este requisito excluye la mayoría de los métodos existentes. En segundo lugar, como se mencionó anteriormente, no existe un acuerdo común sobre un método de detección de la comunidad para todo uso. Esto se debe a la ausencia de una definición compartida de la comunidad, que se justifica por la naturaleza del problema en sí. En consecuencia, existe también la arbitrariedad en la definición de los procedimientos de ensayo fiables para los algoritmos. Sin embargo, existe un amplio consenso sobre la definición de comunidad originalmente introducido en un artículo de Condon y Karp [23]. La idea es que una red tiene comunidades si la probabilidad de que dos nodos de una misma comunidad están conectados excede la probabilidad de que los nodos de diferentes comunidades están conectados. Este concepto de comunidad se ha implementado para crear clases de grafos de referencia con las comunidades, tales como los introducidos por Girvan y Newman [11] y los grafos diseñados recientemente por Lancichinetti et al. [24], que integran al índice de referencia Girvan y Newman con distribuciones realistas de grado y el tamaño de la comunidad (LFR referencia). Investigaciones recientes indican que algunos algoritmos funcionan muy bien en el punto de referencia LFR [25]. En particular, el método introducido por Infomap Rosvall y Bergstrom [26] tiene una destacada actuación, y también es rápido y por lo tanto adecuado para grandes redes. Sin embargo, como todos los métodos de detección comunidad tiene su propio "sabor" y la preferencia hacia el etiquetado de determinados tipos de estructura de las comunidades, depender de un solo método no es suficiente si las conclusiones generales sobre la estructura de la comunidad deben ser presentados. Por lo tanto hemos verificado de forma cruzada los resultados obtenidos por Infomap con los producidos por un algoritmo muy diferente, la etiqueta de Propagación Método (LPM), propuesto por Leung et al. [27]. Este último ha demostrado ser fiable en el punto de referencia LFR y también es lo suficientemente rápido para manejar los sistemas más grandes de nuestra colección. Las descripciones detalladas de Infomap y la LPM se dan en el Apéndice S1. Aquí acabamos de señalar las profundas diferencias entre las dos técnicas. Infomap es un método de optimización global, que tiene como objetivo optimizar una función que expresa la calidad de la longitud del código de un paseo aleatorio de longitud infinita que tiene lugar en el grafo. El LPM es un método local, donde los nodos se atribuyen a la misma comunidad donde la mayoría de sus vecinos son. Las particiones obtenidos por ambos métodos para la misma red están en diferente general. Sin embargo, las características estadísticas generales de la estructura de la comunidad no parecen depender mucho de los detalles de las particiones. En lo que sigue, sólo se presentaron los resultados Infomap; para LPM, véase el Apéndice S1.
Resultados
Comenzamos el análisis por discutir brevemente la distribución de tamaños de la comunidad (Fig. 1). Vemos que, como era de esperar, para cada sistema hay una amplia gama de tamaños de la comunidad, que abarca varios órdenes de magnitud para los sistemas más grandes. Esto está de acuerdo con estudios anteriores [12], [16] - [19]. Las formas generales de las distribuciones son sistemas similares a través de la misma clase. Las distribuciones de las redes biológicas muestran las diferencias más grandes, que, sin embargo, es probable que el resultado de ruido como las redes son más pequeñas. Para las redes biológicas, el análisis realizado con el LPM muestra ligeramente diferentes distribuciones, así superpuestos (véase el Apéndice S1).Figura 1. Distribución de tamaños de la comunidad.
Todas las distribuciones son amplios, y similar para los sistemas de la misma categoría. Los puntos de datos son promedios dentro de contenedores logarítmicas del tamaño del módulo.

A continuación, nos dirigimos a la topología de las comunidades, y estudiamos la densidad de enlace de las comunidades y su dependencia del tamaño de la comunidad. La densidad de enlace de un subgrafo se define como la fracción de enlaces existentes a posibles enlaces,
 donde
donde  es el número de sus enlaces internos y su tamaño se mide en los nodos. Aquí, utilizamos la densidad de enlace a escala
es el número de sus enlaces internos y su tamaño se mide en los nodos. Aquí, utilizamos la densidad de enlace a escala  , que también equivale aproximadamente al grado promedio interna de nodos en la comunidad. Hemos elegido esta medida, ya que señala claramente la naturaleza de subgrafos. Para los árboles, siempre hay
, que también equivale aproximadamente al grado promedio interna de nodos en la comunidad. Hemos elegido esta medida, ya que señala claramente la naturaleza de subgrafos. Para los árboles, siempre hay  enlaces, y por lo tanto
enlaces, y por lo tanto  . Por otro lado, para cliques completo
. Por otro lado, para cliques completo 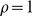 y por lo tanto
y por lo tanto  .
.La Figura 2 muestra el promedio de las densidades escalados de enlaces
 como función del tamaño de la comunidad para diferentes redes. Las líneas discontinuas indican los casos límite (
como función del tamaño de la comunidad para diferentes redes. Las líneas discontinuas indican los casos límite ( ). Vemos que las densidades de enlace en las redes de comunicación e Internet son muy cerca del límite inferior, lo que significa que sus comunidades son en forma de árbol y contienen pocos o ningún bucle. En las redes de comunicación, la densidad de enlace reducido no depende del tamaño de la comunidad, mientras que en los grafos de grandes comunidades de Internet parecen algo más densa. Redes en estas dos clases son los más escasa en nuestra colección, como su muy pequeño grado medio indica que en general no son mucho más densos que los árboles (ver Tabla 1). Cabe señalar que, en general, la vista intuitiva en las comunidades es que son "denso" en comparación con el resto de la red. Sin embargo, como los métodos aplicados aquí producen particiones, las comunidades de una red en forma de árbol son también necesariamente árbol similar. Contrariamente a lo anterior, las redes de información mucho más denso revelan una imagen diferente, donde las comunidades son bastante objetos densos, con la densidad de escala creciente con s. Especialmente en la red de Amazon, las comunidades con
). Vemos que las densidades de enlace en las redes de comunicación e Internet son muy cerca del límite inferior, lo que significa que sus comunidades son en forma de árbol y contienen pocos o ningún bucle. En las redes de comunicación, la densidad de enlace reducido no depende del tamaño de la comunidad, mientras que en los grafos de grandes comunidades de Internet parecen algo más densa. Redes en estas dos clases son los más escasa en nuestra colección, como su muy pequeño grado medio indica que en general no son mucho más densos que los árboles (ver Tabla 1). Cabe señalar que, en general, la vista intuitiva en las comunidades es que son "denso" en comparación con el resto de la red. Sin embargo, como los métodos aplicados aquí producen particiones, las comunidades de una red en forma de árbol son también necesariamente árbol similar. Contrariamente a lo anterior, las redes de información mucho más denso revelan una imagen diferente, donde las comunidades son bastante objetos densos, con la densidad de escala creciente con s. Especialmente en la red de Amazon, las comunidades con  son casi camarillas. Las redes sociales muestran aún otro patrón: la densidad de escalado de los módulos crece bastante regularmente con el tamaño, aproximadamente como una ley de potencia. Comunidades en las redes sociales son en su mayoría muy lejos de los dos casos límite: son más densos que los árboles, pero mucho más escasa que camarillas, con la excepción de las pequeñas comunidades que aparecen más árbol similar. Por último, las redes biológicas se caracterizan por dos regímenes: para
son casi camarillas. Las redes sociales muestran aún otro patrón: la densidad de escalado de los módulos crece bastante regularmente con el tamaño, aproximadamente como una ley de potencia. Comunidades en las redes sociales son en su mayoría muy lejos de los dos casos límite: son más densos que los árboles, pero mucho más escasa que camarillas, con la excepción de las pequeñas comunidades que aparecen más árbol similar. Por último, las redes biológicas se caracterizan por dos regímenes: para  , las comunidades son muy similares a árboles; para valores más grandes de s la densidad escalada aumenta con s. En la Figura 3 se ilustran las comunidades características de las clases de red.
, las comunidades son muy similares a árboles; para valores más grandes de s la densidad escalada aumenta con s. En la Figura 3 se ilustran las comunidades características de las clases de red.Figura 2. Densidad escalada de enlaces de las comunidades como una función del tamaño de la comunidad.
Las redes de comunicación e Internet consisten esencialmente de las comunidades de árboles similares, mientras que las comunidades de redes sociales e información son mucho más denso. Pequeños módulos en redes biológicas son a menudo árbol similar, mientras que los módulos de mayor tamaño son más densos. Los puntos de datos son promedios dentro de contenedores logarítmicas del tamaño del módulo s.

Figura 3. Ejemplos visualizada de las comunidades en las redes de diferentes clases.
Las redes de comunicación (a: correo electrónico, b: Wiki Discusión) contienen comunidades muy dispersas con cubos en forma de estrella. Estos centros dan lugar a muy bajo longitudes de camino más corto dentro de las comunidades (ver Fig. 2). cubos parecidos a estrellas también están presentes en las comunidades de Internet (C: Dimes, d: Caida), que son relativamente escasas también. La comunidad CAIDA muestra una estructura de "estrellas fusionado" bastante típico de estas redes (véase el Apéndice S1). Por el contrario, las redes de información contienen densas comunidades hasta grandes camarillas (e: Amazon, f: Web-BS). En las redes biológicas, cuanto mayor sea la comunidad, menos del árbol-como es (g: D. melanogaster, h: H. sapiens). Por último, las comunidades en las redes sociales aparecen en promedio bastante homogénea (i: Slashdot, j: Epinions).
La compacidad de las comunidades se puede medir utilizando la longitud del camino más corto promedio dentro de cada comunidad. Higo. 4 muestra los valores medios de en función del tamaño de la comunidad. Para todas las redes, las longitudes medias camino más corto son muy pequeñas, con la excepción de las redes sociales. Curiosamente, todas las parcelas revelan el mismo patrón básico, con independencia de la clase de red. Para las comunidades muy pequeñas, crece aproximadamente como el logaritmo del tamaño de la comunidad (indicado por la línea de puntos), que es la propiedad "mundo pequeño" se observa típicamente en redes complejas [28]. Llamamos a estos módulos microcomunidades. Para los tamaños del orden de, sin embargo, el aumento de repente se vuelve menos pronunciada, y varias curvas de alcanzar una meseta. Los módulos con nodos son macrocommunidades. La estabilización de la longitud del camino más corto medio en macrocommunidades se puede atribuir a la presencia de nodos con alto grado, es decir, cubos, que hacen caminos geodésicos en promedio corto. Hacemos notar que, dado que la mayoría de nuestros sistemas tienen grado distribuciones amplias, más cortas longitudes de paso son muy cortos [29], pero la brusca transición que observamos es inesperada y aparece como una característica completamente nueva.
Figura 4. El camino más corto promedios de duración dentro de las comunidades como una función del tamaño de la comunidad.
Después de un régimen inicial logarítmica "mundo pequeño" (línea de trazos en diagonal), el camino más corto promedio crece mucho más lento o se satura para las comunidades con nodos (línea punteada vertical). Los puntos de datos son promedios dentro de contenedores logarítmicas de tamaño del módulo.

Para las redes de comunicación, hay una meseta con
 para
para  . A medida que estas comunidades son en forma de árbol, esto indica que tienen una estructura semejante a una estrella donde la mayoría de los nodos están conectados a un concentrador central única y por lo tanto es igual a dos su distancia. Para las redes de Internet, la presencia conjunta de baja densidad y baja distancias también significa que los cubos dominan la estructura - aquí, estructuras "-combinado de la estrella" que consta de dos o más ejes que comparten muchos de sus vecinos fueron observados (véase la figura 3d.). Esta estructura garantiza una comunicación eficiente entre las unidades de los sistemas. Por el contrario, la información, social, y redes biológicas tener una densidad más alta y por lo tanto sus longitudes de trayectoria cortas son debido tanto a la densidad y la presencia de concentradores. Hubs juegan un papel menor en las redes sociales, ya que las longitudes medias camino más corto siguen aumentando poco a poco también para grandes.
. A medida que estas comunidades son en forma de árbol, esto indica que tienen una estructura semejante a una estrella donde la mayoría de los nodos están conectados a un concentrador central única y por lo tanto es igual a dos su distancia. Para las redes de Internet, la presencia conjunta de baja densidad y baja distancias también significa que los cubos dominan la estructura - aquí, estructuras "-combinado de la estrella" que consta de dos o más ejes que comparten muchos de sus vecinos fueron observados (véase la figura 3d.). Esta estructura garantiza una comunicación eficiente entre las unidades de los sistemas. Por el contrario, la información, social, y redes biológicas tener una densidad más alta y por lo tanto sus longitudes de trayectoria cortas son debido tanto a la densidad y la presencia de concentradores. Hubs juegan un papel menor en las redes sociales, ya que las longitudes medias camino más corto siguen aumentando poco a poco también para grandes.La imagen de arriba se ve corroborada por la Fig. 5, que muestra la relación entre la máxima observada grado interna en la comunidad de nodos
 y
y  como una función del tamaño s de la comunidad. Esta relación es igual a la unidad, si cualquier nodo está conectado a todos los otros nodos de su comunidad, y por lo tanto se cuantifica el predominio de los mayores centros dentro de las comunidades. Para las redes de comunicación,
como una función del tamaño s de la comunidad. Esta relación es igual a la unidad, si cualquier nodo está conectado a todos los otros nodos de su comunidad, y por lo tanto se cuantifica el predominio de los mayores centros dentro de las comunidades. Para las redes de comunicación,  es cercano a la unidad, incluso para los s grandes, de acuerdo con las observaciones anteriores sobre las comunidades en forma de estrella. Para Internet, esta cantidad disminuye con un poco, ya que las comunidades pueden contener varios concentradores que no se conectan a todos los demás nodos. En las redes de información, hay algunas diferencias. En los grafos Web, las comunidades más grandes contienen nodos de conexión (casi) toda la comunidad. A medida que la densidad de borde en estas comunidades es alta, puede haber varios de estos nodos - en una pandilla, todos los nodos tienen grado
es cercano a la unidad, incluso para los s grandes, de acuerdo con las observaciones anteriores sobre las comunidades en forma de estrella. Para Internet, esta cantidad disminuye con un poco, ya que las comunidades pueden contener varios concentradores que no se conectan a todos los demás nodos. En las redes de información, hay algunas diferencias. En los grafos Web, las comunidades más grandes contienen nodos de conexión (casi) toda la comunidad. A medida que la densidad de borde en estas comunidades es alta, puede haber varios de estos nodos - en una pandilla, todos los nodos tienen grado  . Para las redes biológicas y sociales, hay una tendencia a la baja. Sobre todo en las redes sociales, hay pocas o ninguna centros dominantes en grandes comunidades. Estamos observación de que el acuerdo entre las curvas de la figura. 5 es más cualitativo que cuantitativo (sobre todo para las redes sociales y biológicas), en desacuerdo con otras firmas. Esto se debe a las parcelas se refieren a las propiedades de una clase muy restringido de nodos "extremales", es decir, de los centros de la comunidad. Por lo tanto, por una parte, el ruido de las curvas es más grande. Por otro lado, los métodos de detección de la comunidad tienen diferentes maneras de tratar a los centros: mientras que los métodos generalmente tienden a ponerlos "dentro de" comunidades, otros (como Infomap) de vez en cuando les ponen "entre" comunidades.
. Para las redes biológicas y sociales, hay una tendencia a la baja. Sobre todo en las redes sociales, hay pocas o ninguna centros dominantes en grandes comunidades. Estamos observación de que el acuerdo entre las curvas de la figura. 5 es más cualitativo que cuantitativo (sobre todo para las redes sociales y biológicas), en desacuerdo con otras firmas. Esto se debe a las parcelas se refieren a las propiedades de una clase muy restringido de nodos "extremales", es decir, de los centros de la comunidad. Por lo tanto, por una parte, el ruido de las curvas es más grande. Por otro lado, los métodos de detección de la comunidad tienen diferentes maneras de tratar a los centros: mientras que los métodos generalmente tienden a ponerlos "dentro de" comunidades, otros (como Infomap) de vez en cuando les ponen "entre" comunidades.Figura 5. La máxima observada grado interno de nodos como una función del tamaño de la comunidad.
Esta cantidad es igual a uno si cualquier nodo está vinculado a todos los demás nodos de su comunidad, y por lo tanto cuantifica el predominio de los centros dentro de las comunidades.

Veamos próxima a echar un vistazo más de cerca a la relación entre los nodos individuales y estructura de la comunidad. Aquí, la propiedad más natural para investigar es el grado interno
 , que indica el número de vecinos de un nodo en su comunidad. Medimos la incrustación de un nodo en su comunidad con la relación
, que indica el número de vecinos de un nodo en su comunidad. Medimos la incrustación de un nodo en su comunidad con la relación  , que caracteriza el grado en que el vecindario del nodo pertenece a la misma comunidad que el propio nodo. La distribución de probabilidad de la relación de arraigo de todos los nodos de sus respectivas redes se muestra en la Fig. 6. Uno directamente puede suponer que, en promedio, el arraigo de nodos sería bastante grande, y una fracción sustancial de sus vecinos deben residir dentro de sus respectivas comunidades. Sin embargo, la Fig. La figura 6 muestra un patrón más complejo, donde los valores
, que caracteriza el grado en que el vecindario del nodo pertenece a la misma comunidad que el propio nodo. La distribución de probabilidad de la relación de arraigo de todos los nodos de sus respectivas redes se muestra en la Fig. 6. Uno directamente puede suponer que, en promedio, el arraigo de nodos sería bastante grande, y una fracción sustancial de sus vecinos deben residir dentro de sus respectivas comunidades. Sin embargo, la Fig. La figura 6 muestra un patrón más complejo, donde los valores  más pequeños de no son nada raro. Todas nuestras redes se caracterizan por una fracción sustancial de los nodos que son totalmente interna a sus comunidades, es decir, que no tienen enlaces a fuera de su comunidad y por lo tanto
más pequeños de no son nada raro. Todas nuestras redes se caracterizan por una fracción sustancial de los nodos que son totalmente interna a sus comunidades, es decir, que no tienen enlaces a fuera de su comunidad y por lo tanto  . Estos corresponden a los puntos de datos más a la derecha en cada parcela, y tales nodos normalmente ascienden a más del 50% todos los nodos. Estos nodos tienen en su mayoría un bajo grado (por ejemplo, los grados-uno nodos conectados a hubs en las redes de comunicación). Redes en la misma clase siguen esencialmente un patrón muy similar. Las redes de comunicación e Internet tienen perfiles muy similares a futuro, donde la distribución tiene un pico alrededor de
. Estos corresponden a los puntos de datos más a la derecha en cada parcela, y tales nodos normalmente ascienden a más del 50% todos los nodos. Estos nodos tienen en su mayoría un bajo grado (por ejemplo, los grados-uno nodos conectados a hubs en las redes de comunicación). Redes en la misma clase siguen esencialmente un patrón muy similar. Las redes de comunicación e Internet tienen perfiles muy similares a futuro, donde la distribución tiene un pico alrededor de  . Las redes de información, en cambio, tienen un perfil bastante diferente, con un incremento suave inicial de llegar a una meseta en alrededor
. Las redes de información, en cambio, tienen un perfil bastante diferente, con un incremento suave inicial de llegar a una meseta en alrededor  . Las redes biológicas, a pesar de la inevitable ruido, también muestran una imagen consistente a través de conjuntos de datos. Ellos se asemejan algo a las redes de comunicación y de Internet, con una subida inicial hasta que
. Las redes biológicas, a pesar de la inevitable ruido, también muestran una imagen consistente a través de conjuntos de datos. Ellos se asemejan algo a las redes de comunicación y de Internet, con una subida inicial hasta que  , seguido de un lento descenso para los valores más grandes. Las redes sociales tienen una distribución bastante plana en toda la gama, con pequeñas variaciones de un sistema a otro. Esto significa que hay muchos nodos con la mayor parte de sus vecinos fuera de su comunidad. La mayoría de las técnicas de detección de la comunidad, incluidos los que hemos adoptado, tienden a asignar a cada nodo de la comunidad, que contiene la mayor fracción de sus vecinos. Esto implica que si un nodo tiene sólo unos pocos vecinos dentro de su propia comunidad, que tendrá aún menos vecinos dentro de otras comunidades individuales. Dichos nodos actúan como "intermediarios" entre muchos módulos diferentes, y se comparten entre muchas comunidades en lugar de pertenecer a una única comunidad. Por lo tanto, sería más correcto para asignarlos a más de una comunidad. La superposición de las comunidades son conocidos por ser muy comunes en las redes sociales, y se han introducido técnicas especializadas para su detección [16], [30] - [35].
, seguido de un lento descenso para los valores más grandes. Las redes sociales tienen una distribución bastante plana en toda la gama, con pequeñas variaciones de un sistema a otro. Esto significa que hay muchos nodos con la mayor parte de sus vecinos fuera de su comunidad. La mayoría de las técnicas de detección de la comunidad, incluidos los que hemos adoptado, tienden a asignar a cada nodo de la comunidad, que contiene la mayor fracción de sus vecinos. Esto implica que si un nodo tiene sólo unos pocos vecinos dentro de su propia comunidad, que tendrá aún menos vecinos dentro de otras comunidades individuales. Dichos nodos actúan como "intermediarios" entre muchos módulos diferentes, y se comparten entre muchas comunidades en lugar de pertenecer a una única comunidad. Por lo tanto, sería más correcto para asignarlos a más de una comunidad. La superposición de las comunidades son conocidos por ser muy comunes en las redes sociales, y se han introducido técnicas especializadas para su detección [16], [30] - [35].Figura 6. Distribución de probabilidad para ISA
 , la fracción de los vecinos de un nodo que pertenece a su propia comunidad.
, la fracción de los vecinos de un nodo que pertenece a su propia comunidad.Redes en la misma clase presentan un comportamiento similar.

En el Apéndice S1 se investigan otras propiedades estadísticas de las comunidades.
Discusión
Desde el advenimiento de la ciencia de las redes complejas, su atención se ha desplazado desde la comprensión de la aparición y la importancia de las características a nivel de sistema para mesoscopic propiedades de las redes. Estos se manifiestan en las comunidades, es decir subgraphs densamente conectada. Las comunidades son ubicuos en las redes y por lo general juegan un papel importante en la función de un sistema complejo - módulos en las redes de interacción proteína-se refieren a funciones biológicas específicas, y las comunidades en las redes sociales representan el nivel fundamental de la organización en una sociedad. El doble problema de definir formalmente y detectar con precisión las comunidades ha atraído hasta ahora la mayor parte de la atención, a costa de una falta de comprensión de las propiedades estructurales fundamentales de las comunidades. Nuestro objetivo en este trabajo ha sido el de descubrir algunas de estas propiedades.Nuestros resultados indican que las comunidades detectados en las redes de la misma pantalla clase características estructurales sorprendentemente similares. Esto es notable, ya que algunas clases son muy amplio y comprenden sistemas de diferente origen (por ejemplo, la clase de redes de información, que incluye grafos de citación, co-compra y la Web). El resultado se verifica mediante dos métodos de detección de la comunidad que son diferentes tanto partición-basan, pero se basan en principios completamente diferentes. De acuerdo con los resultados anteriores, las distribuciones de tamaño de la comunidad son amplios para todos los sistemas que hemos estudiado. densidades de enlace dentro de las comunidades dependen en gran medida de la clase de red. La longitud media de camino más corto muestra un comportamiento similar en todas las clases, en un principio aumentará de manera logarítmica en función del tamaño de la comunidad (microcomunidades) y luego la ralentización o la saturación de las comunidades de tamaño
 (macrocommunities). En combinación con nuestros resultados en la densidad de enlace en las comunidades, el comportamiento de las longitudes de trayectoria revela un cuadro donde los nodos de alto grado son muy dominantes en las comunidades de ciertas clases (de comunicación, Internet) y juega un papel menos importante en la conectividad de los demás, especialmente redes sociales. Esta imagen se ve corroborada por el análisis de los grados internos en la comunidad máximas de nodos. Por último, también la distribución de probabilidad de la fracción de los enlaces internos para los nodos muestra una firma clara para cada una de las clases consideradas.
(macrocommunities). En combinación con nuestros resultados en la densidad de enlace en las comunidades, el comportamiento de las longitudes de trayectoria revela un cuadro donde los nodos de alto grado son muy dominantes en las comunidades de ciertas clases (de comunicación, Internet) y juega un papel menos importante en la conectividad de los demás, especialmente redes sociales. Esta imagen se ve corroborada por el análisis de los grados internos en la comunidad máximas de nodos. Por último, también la distribución de probabilidad de la fracción de los enlaces internos para los nodos muestra una firma clara para cada una de las clases consideradas.Las firmas que hemos encontrado son una especie de identificación de la red, y podrían utilizarse tanto para clasificar otros sistemas e identificar nuevas clases de red. Por otra parte, podrían convertirse en elementos esenciales de los modelos de red, con la ventaja de las descripciones más precisas de las redes reales y las predicciones de su evolución.
Aunque nuestros resultados se han obtenido utilizando dos métodos diferentes, sus méritos generales de validez alguna discusión. A medida que el concepto de "comunidad" es mal definido, todos los métodos para la detección de las comunidades se basa en una interpretación específica del concepto. Además, las filosofías subyacentes de los métodos pueden diferir en gran medida. Métodos que requieren que las comunidades son "local" muy densa, como camarilla percolación [16], detectaría sólo unas pocas comunidades en las redes de comunicación e Internet, ya que no tienen en cuenta los árboles o estrellas como comunidades - sin embargo, este resultado sería coherente para las redes de la misma clase. Por otra parte, es evidente que los métodos basados en particiones descuidar el hecho de que los nodos pueden participar en múltiples comunidades. Sin embargo, vale la pena señalar que cualquiera que sea el método utilizado, las comunidades resultantes son subgrafos reales de la red en estudio, es decir, sus bloques de construcción. Por lo tanto sus propiedades estadísticas reflejan la organización mesoscópicas de las redes, y nuestros resultados indican que esta organización es similar dentro de las clases de redes.
Un artículo muy reciente [36] ha llegado a una conclusión similar con un enfoque totalmente diferente, donde las taxonomías de redes se construyeron sobre la base de firmas derivadas de la modularidad de Newman y Girvan.
Referencias
1. Albert R, Jeong H, Barabási AL (2000) Error and attack tolerance of complex networks. Nature 406: 378–382.View Article
PubMed/NCBI
Google Scholar
2. Albert R, Barabási AL (2002) Statistical mechanics of complex networks. Rev Mod Phys 74: 47–97.
View Article
PubMed/NCBI
Google Scholar
3. Boccaletti S, Latora V, Moreno Y, Chavez M, Hwang DU (2006) Complex networks: Structure and dynamics. Phys Rep 424: 175–308.
View Article
PubMed/NCBI
Google Scholar
4. Newman MEJ (2003) The structure and function of complex networks. SIAM Rev 45: 167–256.
View Article
PubMed/NCBI
Google Scholar
5. Dorogovtsev SN, Mendes JFF (2002) Evolution of networks. Adv Phys 51: 1079–1187.
View Article
PubMed/NCBI
Google Scholar
6. Pastor-Satorras R, Vespignani A (2004) Evolution and Structure of the Internet: A Statistical Physics Approach. New York, NY, USA: Cambridge University Press.
7. Barrat A, Barthélemy M, Vespignani A (2008) Dynamical processes on complex networks. Cambridge, UK: Cambridge University Press.
8. Caldarelli G (2007) Scale-free networks. Oxford, UK: Oxford University Press.
9. Cohen R, Erez K, ben Avraham D, Havlin S (2000) Resilience of the internet to random breakdowns. Phys Rev Lett 85: 4626–4628.
View Article
PubMed/NCBI
Google Scholar
10. Pastor-Satorras R, Vespignani A (2001) Epidemic spreading in scale-free networks. Phys Rev Lett 86: 3200–3203.
View Article
PubMed/NCBI
Google Scholar
11. Girvan M, Newman ME (2002) Community structure in social and biological networks. Proc Natl Acad Sci USA 99: 7821–7826.
View Article
PubMed/NCBI
Google Scholar
12. Danon L, Duch J, Arenas A, Díaz-Guilera A (2007) Community structure identification. In: G C, A V, editors. Large Scale Structure and Dynamics of Complex Networks: From Information Technology to Finance and Natural Science. Singapore: World Scientific. pp. 93–114.
13. Porter MA, Onnela JP, Mucha PJ (2009) Communities in networks. Notices of the American Mathematical Society 56: 1082–1097.
View Article
PubMed/NCBI
Google Scholar
14. Fortunato S (2010) Community detection in graphs. Physics Reports 486: 75–174.
View Article
PubMed/NCBI
Google Scholar
15. Simon H (1962) The architecture of complexity. Proc Am Phil Soc 106: 467–482.
View Article
PubMed/NCBI
Google Scholar
16. Palla G, Derényi I, Farkas I, Vicsek T (2005) Uncovering the overlapping community structure of complex networks in nature and society. Nature 435: 814–818.
View Article
PubMed/NCBI
Google Scholar
17. Newman MEJ (2004) Detecting community structure in networks. Eur Phys J B 38: 321–330.
View Article
PubMed/NCBI
Google Scholar
18. Clauset A, Newman MEJ, Moore C (2004) Finding community structure in very large networks. Phys Rev E 70: 066111.
View Article
PubMed/NCBI
Google Scholar
19. Radicchi F, Castellano C, Cecconi F, Loreto V, Parisi D (2004) Defining and identifying communities in networks. Proc Natl Acad Sci USA 101: 2658–2663.
View Article
PubMed/NCBI
Google Scholar
20. Leskovec J, Backstrom L, Kumar R, Tomkins A (2008) Microscopic evolution of social networks. KDD '08: Proceeding of the 14th ACM SIGKDD international conference on Knowledge discovery and data mining. New York, NY, USA: ACM,. pp. 462–470.
21. Bollobas B (1998) Modern Graph Theory. New York, USA: Springer Verlag.
22. Guimerà R, Amaral LAN (2005) Functional cartography of complex metabolic networks. Nature 433: 895–900.
View Article
PubMed/NCBI
Google Scholar
23. Condon A, Karp RM (2001) Algorithms for graph partitioning on the planted partition model. Random Struct Algor 18: 116–140.
View Article
PubMed/NCBI
Google Scholar
24. Lancichinetti A, Fortunato S, Radicchi F (2008) Benchmark graphs for testing community detection algorithms. Phys Rev E 78: 046110.
View Article
PubMed/NCBI
Google Scholar
25. Lancichinetti A, Fortunato S (2009) Community detection algorithms: A comparative analysis. Phys Rev E 80: 056117.
View Article
PubMed/NCBI
Google Scholar
26. Rosvall M, Bergstrom CT (2008) Maps of random walks on complex networks reveal community structure. Proc Natl Acad Sci USA 105: 1118–1123.
View Article
PubMed/NCBI
Google Scholar
27. Leung IXY, Hui P, Liò P, Crowcroft J (2009) Towards real-time community detection in large networks. Phys Rev E 79: 066107.
View Article
PubMed/NCBI
Google Scholar
28. Watts D, Strogatz S (1998) Collective dynamics of ‘small-world’ networks. Nature 393: 440–442.
View Article
PubMed/NCBI
Google Scholar
29. Chung F, Lu L (2002) The average distances in random graphs with given expected degrees. Proc Natl Acad Sci USA 99: 15879–15882.
View Article
PubMed/NCBI
Google Scholar
30. Zhang S, Wang RS, Zhang XS (2007) Identification of overlapping community structure in complex networks using fuzzy c-means clustering. Physica A 374: 483–490.
View Article
PubMed/NCBI
Google Scholar
31. Gregory S (2007) An algorithm to find overlapping community structure in networks. Proceedings of the 11th European Conference on Principles and Practice of Knowledge Discovery in Databases (PKDD 2007). Berlin, Germany: Springer-Verlag. pp. 91–102.
32. Li D, Leyva I, Almendral JA, Sendiña-Nadal I, Buldú JM, et al. (2008) Synchronization interfaces and overlapping communities in complex networks. Phys Rev Lett 101: 168701.
View Article
PubMed/NCBI
Google Scholar
33. Lancichinetti A, Fortunato S, Kertesz J (2009) Detecting the overlapping and hierarchical community structure in complex networks. New J Phys 11: 033015.
View Article
PubMed/NCBI
Google Scholar
34. Evans TS, Lambiotte R (2009) Line graphs, link partitions, and overlapping communities. Phys Rev E 80: 016105.
View Article
PubMed/NCBI
Google Scholar
35. Sawardecker EN, Sales-Pardo M, Amaral LAN (2009) Detection of node group membership in networks with group overlap. Eur Phys J B 67: 277–284.
View Article
PubMed/NCBI
Google Scholar
36. Onnela JP, Fenn DJ, Reid S, Porter MA, Mucha PJ, et al. (2010) A Taxonomy of Networks. ArXiv e-prints 1006.5731:
View Article
PubMed/NCBI
Google Scholar
No hay comentarios:
Publicar un comentario