
Visualizaciones fáciles de PageRank y grupos de páginas con Gephi
Search Engine Land

En abril del año pasado, colaborador Search Engine Land Paul Shapiro ha escrito una entrada brillante sobre el cálculo de PageRank interna. El puesto ha esbozado método para examinar los enlaces internos de un sitio web con el fin de determinar la importancia de las páginas web dans le.
Esto es asombroso de gran alcance, el objetivo Creo que el concepto de Pablo podría ser más fácil de usar. Utilizó R, qui es un lenguaje y entorno de computación estadística, y la salida es básicamente un montón de números.
Quiero que le muestre cómo hacer los Sami en Gephi con sólo pulsar unos pocos botones en lugar de un montón de código - y, con unos pocos clics más, puede visualizar los datos de una manera que se siente orgulloso de mostrar a sus clientes .
Te voy a mostrar cómo obtener este resultado como un ejemplo de cómo Gephi puede ser útil en sus esfuerzos de SEO. Podrás ble para ver qué páginas son las más fuertes es sus páginas web, páginas determinan cómo se pueden agrupar por temas e identificar algunas cuestiones de sitios web comunes, tales como errores de rastreo o pobres de enlaces internos. A continuación voy a describir algunas ideas para Tomando el concepto al siguiente nivel de geek.
¿Qué es Gephi?
Gephi es un software de código abierto se utiliza para representar gráficamente que las redes y se utiliza comúnmente para representar las redes informáticas y redes de medios sociales.Es un programa de escritorio simple, basada en Java que se ejecuta en Windows, Mac o Linux. Aunque la versión actual de Gephi es 0.9.1, le animo a descargar la versión anterior 0.9.0, o más tarde la versión 0.9.2, en su lugar. De esa manera usted será ble para seguir aquí, y evitará los errores y los dolores de cabeza de la versión actual. (Si no has-hecho recientemente, puede que tenga que instalar Java en su ordenador también.)
1. Para empezar, el rastreo de su sitio web y la recopilación de datos
Normalmente uso Screaming Frog para el rastreo. Dado que estamos interesados en las páginas aquí y no otros archivos, tendrá que excluir cosas de los datos de rastreo.Para hacer eso, Aquellos de ustedes con la versión de pago de los deberes de software Implementar la configuración que voy a describir a continuación. (Si está utilizando los límites de versión libre que a qui la recogida de 500 URL y no le permiten ajustar la configuración muchos tienen, voy a explicar qué hacer después.)
Ir a “Configuration” > “Spider” y verá algo parecido a la siguiente captura de pantalla. Haga que el suyo que coincida con la mía para los mejores resultados. Normalmente aussi añadir .*(png|jpg|jpeg|gif|bmp)$ a “Configuration” > “Exclude” para deshacerse de las imágenes, qui Screaming Frog deja veces en el retraso de rastreo.
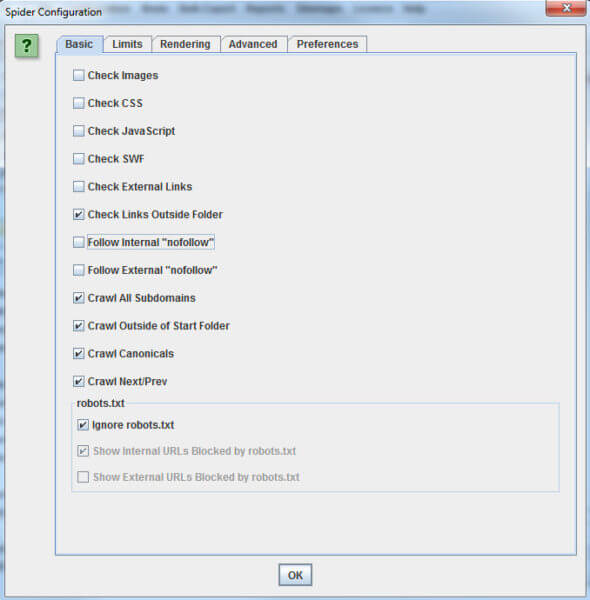
Para iniciar el rastreo, podría URL de su sitio en el espacio en la parte superior izquierda (foto de abajo). A continuación, haga clic en "Inicio" y esperar a que el rastreo hasta el final.

Cuando se termina el rastreo, vaya a “Bulk Export” > “All Inlinks.” Usted querrá cambiar “Files of Type” a “.csv” y guardar el archivo.
La limpieza de la hoja de cálculo
- Eliminar la primera fila que contiene “All Inlinks.”
- Eliminar la primera columna, “Type.”
- Cambie el nombre del "destino" a la columna "Target".
- Eliminar todas las demás columnas Además de “Source” y “Target.”.
- Guardar el archivo editado (y puedes volver a hacer un uso seguro del tipo de archivo es .csv).

Opcionalmente, puede dejar otras columnas como código de estado o de texto de enlace si desea que este tipo de datos es la gráfica. Los dos principales campos que voy a estar explicando cómo utilizar son “Source” y “Target.”
Si está utilizando la versión gratuita de Screaming Frog, tendrá que hacer un montón de trabajo de limpieza para filtrar las imágenes, archivos CSS y JavaScript.
En Excel, si vas a "Insertar" y haga clic en "Tabla", obtendrá una ventana emergente. Haga su caja fuerte de datos ha-ha definido correctamente, haga clic en "Mi TIENE encabezados de tabla", y haga bien. Ahora, seleccione la flecha en la parte superior derecha de la columna "Target", y un cuadro de búsqueda aparecerá. Lo utilizan para filtrar las filas de la tabla para identificar que contienen las extensiones para los diferentes tipos de archivos, como .js o .css.
Una vez que tenga una visión de todas las filas de la tabla que tienen uno infractor tipo de archivo, seleccionar y eliminar toda la información para aquellas filas. Haga esto para cada tipo de archivo de la antes mencionada y presentar cualquier tipo de imágenes como .jpg, .jpeg, .png, .gif, .bmp o cualquier otra cosa. Cuando haya terminado, es necesario guardar el archivo como .csv de nuevo.
2. Uso Gephi para visualizar los datos de rastreo

Importación de nuestros datos
- En la pantalla emergente que aparece al abrir la aplicación, haga clic en “New Project.”
- A continuación, seleccione “File” > “Import Spreadsheet.”
- Elija su archivo .csv y hacer seguro el “Separator” se establece como “Comma” y “As table” se establece como “Edges table.” Si usted tuviera que hacer un montón de limpieza de datos de Excel, haga amargo que ha eliminado cualquier filas en blanco dentro de sus datos antes de importarlo.
- Haga clic en “Next,” y asegúrese de que “Create missing nodes” se comprueba antes de pulsar "Finish".
Para nuestros propósitos - Visualización de enlaces internos - los "Edges" son los enlaces internos, y "nodos" son diferentes páginas de la web. (Nota: Si se tropieza con un error de memoria, puede aumentar la cantidad de memoria en Asignado por Gephi Siguiendo esta guía).
Si realmente-tienen un amplio conjunto de datos o desea combinar varios conjuntos de datos, puede importar varios archivos en Gephi.
Una vez que todos los datos están en el "Laboratorio de Datos", se puede cambiar a "Información general". A continuación, verá un cuadro negro probable como la de abajo. No se preocupe, vamos a hacer que bonita en un minuto.

El cálculo de PageRank y modularidad
En la pestaña "Estadísticas", ejecute "PageRank" y "Modularidad". (Seleccionar "ventana" y "Estadísticas" si usted no ve la pestaña "Estadísticas").Recomiendo el uso de la configuración predeterminada de PageRank, el objetivo de modularidad que lo haría destildaría "Use pesos." Esto añadirá los datos acerca de sus páginas en nuevas columnas que serán utilizados para la visualización.

Es posible que tenga que ejecutar modularidad un par de veces para hacer las cosas de la manera deseada 'em. racimos modularidad páginas que están más conectados con one modularidad otra en grupos o clases (cada par représentée un número). Usted tendrá que formar grupos de páginas que son lo suficientemente grande como para ser significativo, pero lo suficientemente pequeño como para obtener su cabeza alrededor.
Estás clustering, después de todo, por lo que la agrupación de todas sus páginas en dos o tres grupos, probablemente, trae un montón de cosas juntos diferencia. Propósito si al final con 200 racimos, eso no es del todo útil, tampoco. En caso de duda, el objetivo de un mayor número de grupos, ya que muchos de los grupos será probablemente muy pequeño y los deberes agrupaciones mano aún ser revelado.
No se preocupe, te voy a mostrar cómo comprobar y ajustar sus grupos en un minuto. (Nota :. Un menor modularidad le dará más grupos y A modularidad Superior le dará grupos Menos Tweak esto mediante fracciones en lugar de números enteros, como un pequeño cambio hace una gran diferencia).
Ajustar su configuración Modularidad
Vamos a ver lo que hemos hecho. Cambiar la pestaña de "Laboratorio de Datos" y mirar a la "Tabla de datos." Allí encontrará sus nuevas columnas para PageRank y Clase modularidad. Los deberes números de PageRank se alinean con los números de artículo mencionado de Paul Shapiro, el objetivo tesis que tienes que hacer sin tener ningún tipo de codificación. (Recuerde, los números de la tesis de PageRank son internos, no lo hemos Consulte lo general a "PageRank").La modularidad Clase asigna un número a cada página, de modo altamente Eso páginas interconectadas recibe el número de Sami. Utilizar la funcionalidad de filtro en la parte superior derecha para aislar cada página de su grupo, y el globo ocular se examinan algunas de las direcciones URL para ver qué tan cerca están relacionados con la tesis de ser blanco. Si las páginas terminaron en el mal Clase modularidad, es necesario Puede Volver a ajustar la configuración, o podría indicar indicación de que usted no está haciendo un buen trabajo bajo el mecanismo de interconexión feliz.
Recuerde que su modularidad se basa es la vinculación interna, en realidad no el contenido de las páginas, por lo que está identificando aquellas que están normalmente unidos entre sí - Los que no deberías ser unidos entre sí.
En mi caso, he elegido un bufete de abogados y con la configuración predeterminada, que terminó con el desglose siguiente cuando me ordenadas según la modularidad, qui probablemente mejor hecho podría tener con algunos ajustes:
- Clase 0 = lesión
- Clase 1 = familia
- Clase 2 = algunas páginas aleatorias
- Clase 3 = penal
- Clase = 4 tráfico
- Clase 5 = DWI
- Clase 6 = un par de páginas al azar
Puede volver a la pestaña "general" y continuará haciendo ajustes hasta que esté satisfecho con sus grupos de páginas. Incluso se ejecutan varias veces con modularidad números de la même pueden dar resultados diferentes ligeramente cada vez, por lo que puede llevar algún jugando para llegar a un punto de donde usted está satisfecho con los resultados.
Vamos a hacer una foto con Layout
Te prometí una visualización Más temprano, y es probable que te preguntas cuando llegamos a ese recurso compartido. Vamos a hacer que el cuadrado negro en una visualización real de que es más fácil de entender.Ir a "Visión general"> "Diseño". En el cuadro desplegable lado izquierdo donde dice ": elija un diseño," seleccionar "ForceAtlas 2."

Ahora sólo tiene que jugar con los ajustes que para conseguir una visualización que se sienta cómodo. (Si alguna vez se pierde, haga clic en la imagen de la lupa poco en el lado izquierdo de la imagen, y que centrarán y el tamaño de la visualización así que todo es visible en la pantalla.) Para el patrón de la estrella por encima, he puesto "Escala" de 1000 y "gravedad" a 0,7, el resto objetivo son valores predeterminados. Los dos principales ajustes que jugar con escalamiento son probable y gravedad.
Escalamiento gobierna el tamaño de la visualización; El Superior se establece, la más escasa su gráfico será. La manera más fácil de entender la gravedad es pensar en los nodos como los planetas. Cuando aumenta la gravedad, esto atrae todo más cerca. Puede ajustar esta marcando la casilla "Más fuerte gravedad" y ajustando el número de gravedad.
Hay algunas otras opciones, y los efectos son de cada interfaz Explicado dans le. No dude en jugar con ellos (siempre se puede cambiar de nuevo) y ver si hay algo que ayuda a que la visualización más clara.
¿Qué queremos mostrar?
En el caso citado, queremos mostrar modularidad Ambos grupos de páginas () y PageRank interna. La mejor manera que he encontrado para hacer esto es para ajustar el tamaño de los nodos se basa PageRank y los colores se basan modularidad. En la ventana "Aspecto", seleccione "nodos", "Tamaño" (el segundo icono), y en la "pestaña" donde hay un desplegable de "Clasificación Elija un atributo," seleccionar "PageRank".Elija Algunos tamaños y pulsa "Aceptar" hasta que los nodos más importantes son distinguibles de los otros. En la captura de pantalla a continuación, tengo el tamaño mínimo establecido como el 100 y el tamaño máximo en 1.000. Ajuste del tamaño del nodo se basa PageRank le ayuda a identificar fácilmente significativo es sus páginas web - son más grandes.
Para visualizar los grupos de páginas con modularidad, todavía nos queremos estar en la ventana de "Apariencia", el objetivo de este tiempo queremos seleccionar "nodos" "color" (el primer icono), y "Música". En el desplegable hacia abajo para "Elija un atributo," seleccionar "Clase modularidad."
Algunos colores predeterminados están pobladas, meta si desea cambiar ellos, hay un pequeño botón verde de "paleta". En la Paleta, si hace clic en "Generar", puede especificar el número de colores para mostrar basándose se cuántos grupos La modularidad consiguió cuando se ejecuta.
En mi caso, las clases 2 y 6 no eran muy grandes, así que estoy haciendo clic en Cerrar en sus colores y cambiando a em negro. Si desea mostrar sólo un tema específico, cambiar el color de una sola clase modularidad, dejando los otros hicieron comentarios otro color.

Cambio de la visualización
Puede usted desear para etiquetar los nodos de modo que sabemos lo Representan la página. Para agregar una etiqueta con la dirección URL, tenemos que volver a la pestaña "Laboratorio de Datos" y seleccione la tabla de datos. Hay una caja en la parte inferior para "Copiar datos a otra columna," y queremos copiar "ID" para "etiqueta" para obtener las direcciones URL para mostrar. El proceso es similar para los bordes. Si ha guardado el texto de anclaje del rastreo, puede etiquetar cada flanco con el texto del ancla.De nuevo en la pestaña "Ver", tendrá que seleccionar cómo desea que su visualización que se vea. Normalmente selecciono "Default curvo" en virtud de los ajustes preestablecidos, el objetivo de una gran cantidad de personas como "Straight predeterminado".
Cambiar el tamaño de fuente y el tamaño proporcional para las etiquetas ayudará a visualizar em de manera que se pueden leer en diferentes tamaños. Sólo jugar con la configuración de la ficha de vista previa para conseguir que se muestre la forma que desee.
Para la visualización de abajo, he apagado etiquetas de nodo y el borde de manera que no repartiera la identidad del sitio web de la empresa, salvo derecho particular que he utilizado. En su mayor parte, Han hecho un buen trabajo agrupando sus páginas y que une internamente. Si hubiera dejado columna de texto del ancla en la hoja de cálculo de Screaming Frog, podría haber tenido Cada enlace interno (línea) muestra las TIC con el ancla de texto como un sello de borde y cada página enlazada desde (círculos) como una etiqueta de nodo.

Gephi para los conjuntos de datos más grandes
Para los conjuntos de datos más grandes, todavía se puede utilizar Gephi, AUNQUE su gráfico es probable que se parecen más a un mapa estelar. Me graficada los enlaces internos de Search Engine Land, meta que tuvo que ajustar el escalado a 5000 y gravedad a 0,2 en los ForceAtlas 2 ajuste.Todavía se puede ejecutar cálculos de PageRank y modularidad, el propósito es probable que necesite cambiar el tamaño de los ganglios a algo grande para ver Cualquier dato que su gráfico. También puede que tenga que añadir más colores a la paleta, como se describió anteriormente, ya que hay muchas clases de modularidad probables más distintivas en un conjunto de datos de este tamaño. Esto es lo que el gráfico de SEL se ve como antes de teñirlo.

¿Por qué esto tiene alguna importancia?
Gephi se puede utilizar para mostrar una variedad de problemas. En una Anteriormente he publicado en mi artículo sobre el futuro de SEO, que mostró una fractura entre HTTPS y HTTP.Además, se puede descubrir secciones qui puede ser considerado por un cliente significativo que enviaban muy bien conectado internamente. Por lo general, la tesis están más lejos hacia fuera en la visualización debido a la gravedad, y es posible que desee enlazar a ellos más de las páginas de actualidad relacionadas.
Una cosa es decirle a un cliente que necesita más enlaces internos, el objetivo es mucho más fácil para mostrarles que ellos consideran una página a ser significativo En realidad es muy aislado. El cuadro abajo Fue creado por un simple cambio de mi modularidad hasta que sólo tenía dos grupos. Comentarios Este era porque tenía dos enlaces HTTP y HTTPS en mi rastreo, y reduje la modularidad hasta que tenía sólo dos grupos, la mayoría de qui relacionados fueron páginas HTTP > HTTP y páginas HTTPS > HTTPS.

Hay un montón de otras cosas que este tipo de visualización que pueden pista sobre. Busque nodos individuales por sí mismos. Puede usted encontrar tonos de páginas escasas o incluso errores de rastreo. Trampas de araña puede mostrar como una especie de una línea infinita de páginas y páginas que no están en las agrupaciones adecuadas puede significar que enviaban une internamente a partir de ellos las páginas más relevantes.
Un sitio web bien ligado internamente puede parecer más como un círculo que una estrella, y no me parece que es un problema incluso si los colores no siempre se alinean en grupos. Hay que recordar que cada sitio web es única y visualización de cada uno es diferente.

Es difícil de explicar todas las posibilidades, el objetivo si se intenta algunos de estos, usted comenzará a ver los problemas comunes o tal vez incluso algo nuevo y diferente. Estas visualizaciones se permitirá ayudar a los clientes a entender que usted siempre está hablando. Yo te prometí que sus clientes les va a encantar.
Gephi: tiene una serie de opciones para la exportación .png, .svg, .pdf o si desea crear imágenes estáticas. Más divertido es exportar para su uso página web fue por lo que se crea una experiencia interactiva. Para hacer eso, echa un vistazo a los complementos de Gephi - En particular, la exportación y SigmaJS Gexf-JS Web Viewer.
¿Qué más podemos hacer con Gephi?
Añadir información adicional acerca de los vínculos
Si puede-tener un rastreador que identifican el alquiler de los enlaces, se puede ajustar el peso de sus bordes se basa de manera diferente en el alquiler del enlace. Digamos, por ejemplo, que le damos a cada contenido Enlace un valor mayor que, por ejemplo, un sistema de navegación o pie de página de enlaces. Esto nos permite cambiar el cálculo PageRank interno basado en el peso de los enlaces, determinadas por sus alquiler. Que mostraría probable una representación más exacta de cómo Google está valorando probable es que los enlaces en base a su inversión.
Esto nos permite cambiar el cálculo PageRank interno basado en el peso de los enlaces, determinadas por sus alquiler. Que mostraría probable una representación más exacta de cómo Google está valorando probable es que los enlaces en base a su inversión.
Recalando en métricas de terceros para obtener una visión más completa
La visualización que hemos estado trabajando allí hasta el momento ha sido-en base a cálculos internos de PageRank y asume que todas las páginas tienen el mismo peso en la salida. Sabemos, por supuesto, que esta no es la forma en que Google ve las cosas, que cada página habría Enlaces de variable, la fuerza, la clase y la relevancia de ir a ellos desde sitios externos.Para hacer nuestra visualización más compleja y útil, podemos cambiarlo para tirar en las métricas de terceros más que la fuerza interna PageRank. Hay un número de diferentes fuentes para esta información como sea posible, tales como Moz Page Authority, Ahrefs URL Rating, o Majestic Citation Flow o Trust Flow. Cualquiera de estos deben trabajar, por lo que elegir a su favorito. Los deberes resultado ser una representación más exacta de la página web como los motores de búsqueda lo ven, ya que ahora se tiene en cuenta la fuerza de las páginas.
Podemos empezar con el archivo Sami hemos creado para mostrar encima de PageRank interna. En Gephi, vamos a ir a la pestaña "Laboratorio de Datos" y hacer un uso seguro estamos en la pestaña "nodos". Hay una opción "Exportar tabla", y se puede exportar sus columnas en un archivo .csv de su elección. Abrir ese archivo exportado en Excel y crear una nueva columna con cualquier nombre que desee. Me pasó a llamarlo "CF" ya que estoy usando flujo Cita Majestic en mi ejemplo.
Ahora, vamos a incorporar a los datos de terceros. En la hoja de cálculo que exportan desde Gephi, he copiado los datos de Majestic que tiene la página en una columna de flujo y Cita en el segundo. Ahora tenemos que casarse con estos datos a la primera, y se puede hacer esto utilizando una fórmula BUSCARV.
En primer lugar, seleccionar los datos Majestic - Ambas columnas - y convertirlo en un rango con nombre. Para ello, vaya al menú desplegable Insertar y seleccione Nombre. A partir de ahí, elegir la opción "definir" y nombre de rango de sus datos Majestic lo que quiera. Para nuestro ejemplo, lo llamaremos "majestuosa".
A continuación, volver a la columna "CF" en el conjunto de datos original. Haga clic en la primera celda en blanco y tipée =VLOOKUP(A2,majestic,2,FALSE), A continuación, pulsa "Enter" en su teclado. Copiar esto a todas las otras entradas "CF" haciendo doble clic en el pequeño cuadrado en la parte inferior derecha de la caja. Esta fórmula utiliza los datos en la columna A - la URL - tener una llave, y luego hacerlo coincidir con la dirección URL en los datos Majestic Sami. Luego se dirige a la siguiente columna de datos Majestic - los datos PageRank externa que estamos buscando - y tira de ella hacia la columna de la FQ.
A continuación, tendrá que hacer clic en la letra de la columna en la parte superior de la columna de la CF para seleccionar todo en la columna. Haga clic en "CTRL + C" para copiar, a continuación, haga clic derecho e ir a "Pegado especial" en los que aparece y seleccionar el menú "Valores". Esta es nuestra fórmula para reemplazar a los números reales. Ahora podemos eliminar las filas que se había nuestros datos de terceros y salvar a nuestro archivo de nuevo como .csv.
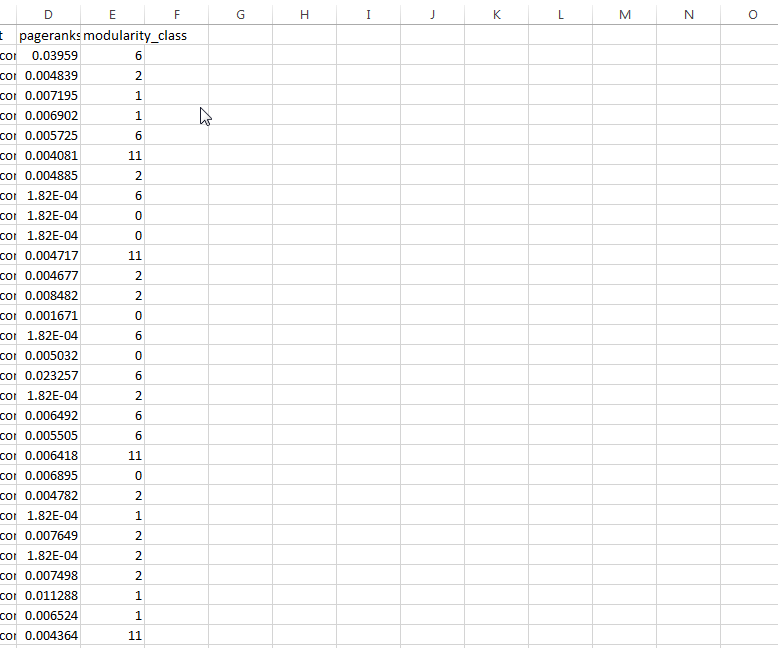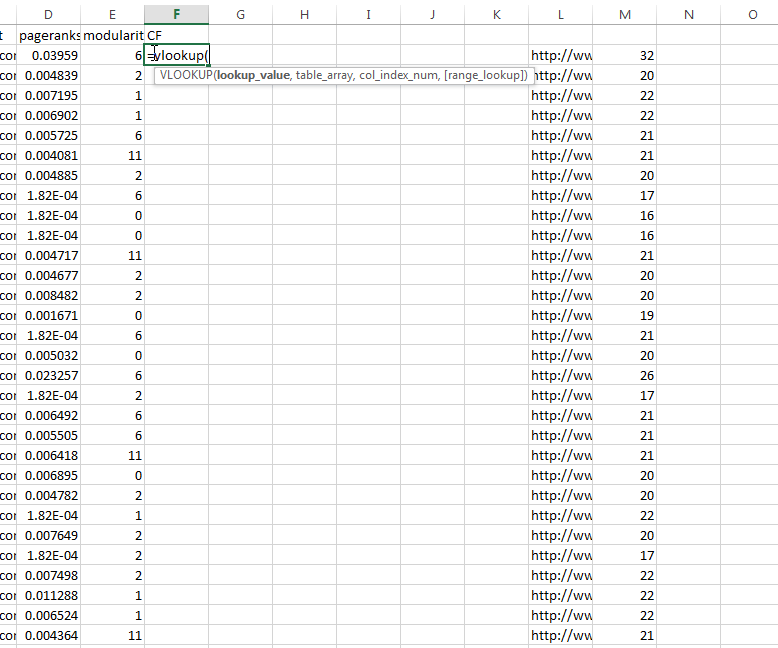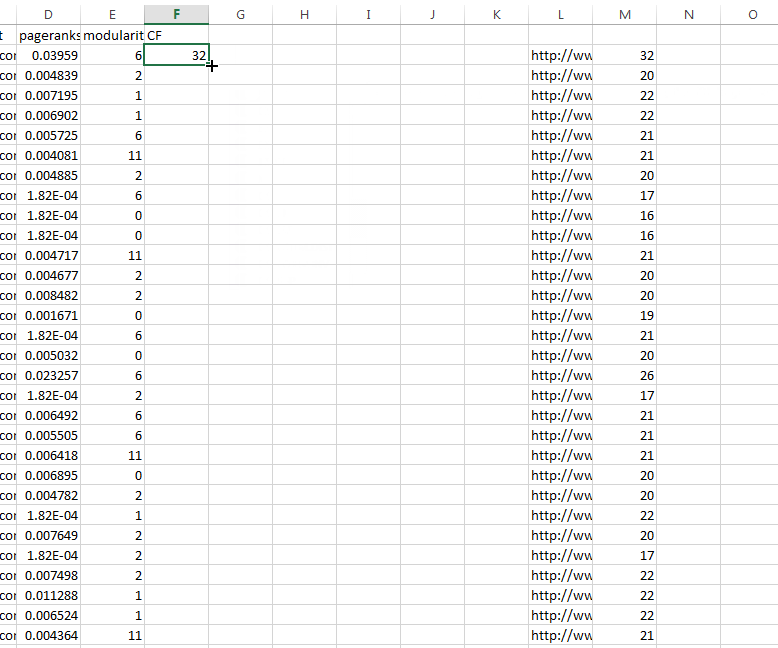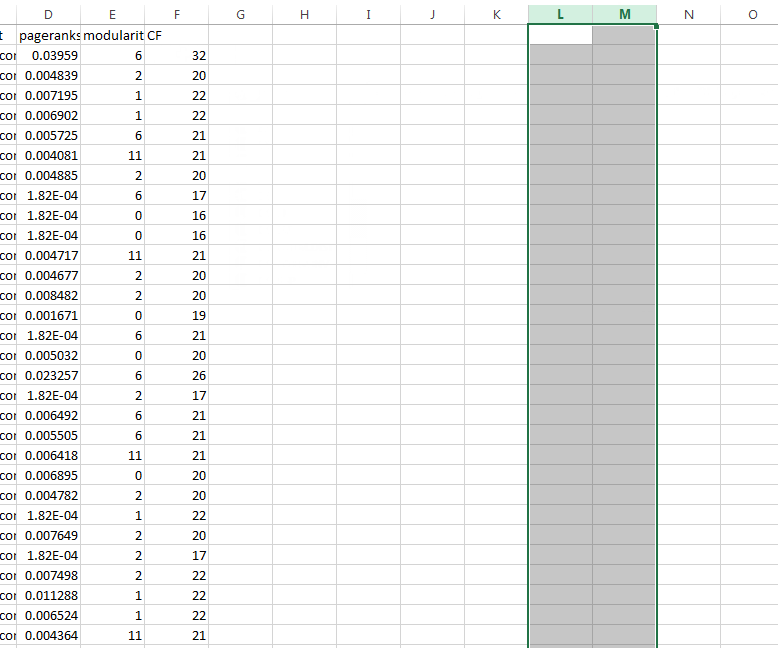
De vuelta en Gephi y en el "Laboratorio de Datos," queremos hacer clic en "Importar hoja de cálculo" para tirar en la tabla que acaba de hacer. Seleccione el archivo .csv creado. Esta vez, a diferencia con los pasos anteriores, queremos cambiar "como mesa" a "mesa de nodos." Haga clic en "Siguiente" y hacer agrio "nodos de fuerza que ser creado como nuevos" no está marcada, después haga clic en "Finalizar". Esta deberes reemplazar la tabla nodos de datos con nuestra tabla modificada que incluye CF.
En la parte inferior de la pantalla de aplicación, verá un botón de "Copiar datos a otra columna." Simplemente queremos seleccionar "CF" y en el "Copiar a" queremos seleccionar "PageRank". Ahora, en vez PageRank interna de los datos generados, estamos utilizando los datos de PageRank externas de terceros.
De vuelta en la pestaña "Información general", queremos mirar en "Apariencia" y pulsa "Aceptar" una vez más. Ahora nuestros nodos deberías ser de un tamaño basado en la fuerza es a partir de nuestros datos CF Majestic. En mi siguiente gráfico, se puede ver qui son las páginas más fuerte en el sitio web, Teniendo en cuenta las medidas externas de la fuerza de las páginas.
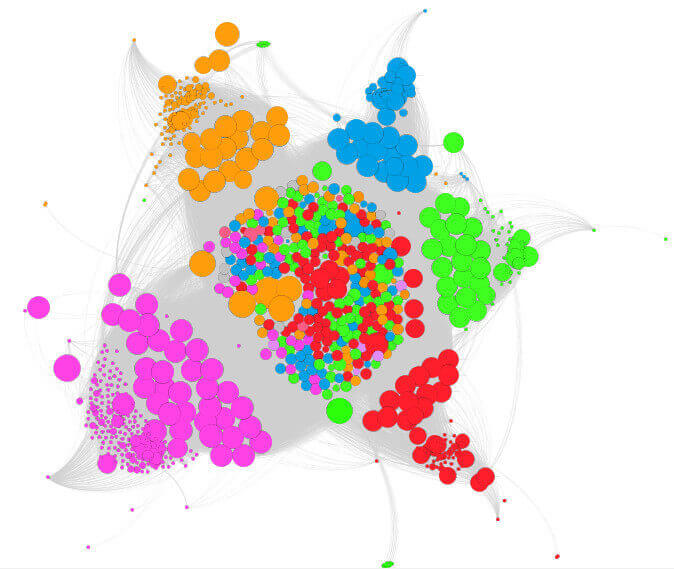
Se puede decir mucho sólo de esta imagen de uno. Cuando se enciende en las etiquetas, se puede ver en cada páginas quien representa cada círculo. El color indica agrupación a cual se agrupa, y el tamaño de círculo indica la fuerza relativa de la página.
La tesis de la parte superior más lejos puntos son, al menos las páginas están vinculadas internamente. Se puede decir por el número de nodos de cada color qué categorías que el cliente ha creado en su mayor feliz y lo que ha sido exitoso para ellos en la atracción de los enlaces externos. Por ejemplo, se puede ver que hay una gran cantidad de puntos de color púrpura, lo que indica que es probable indicación área significativa práctica el año para la empresa y que están creando una gran cantidad de feliz a su alrededor.
El problema es mayor Que la púrpura puntos están más lejos del centro, indicando indicación de que no están bien comunicados internamente. Sin dar demasiado lejos, te puedo decir que muchos de los puntos lejanos a cabo son las entradas del blog. Y mientras lo hacen un buen trabajo de los blogs con enlaces a otras páginas, hacer un trabajo pobre Ellos, por la promoción de sus entradas de blog en el sitio web.














